
If you have a data warehouse and you frequently run queries using aggregate functions like SUM, AVG, COUNT, etc, you need to investigate columnstore indexes. I am going to show you some performance benefits that come from using this new (8 years old now) index type.
First off, I am not going to explain the technical background about them and will instead point you to the following resources that can explain in detail way better than I ever could. I will tell you these should only be used in your warehouse environments and not in your live OLTP databases. Also due to restrictions, they should only be used in SQL Server 2016 and greater. Previous versions you could not update them and had to delete them before every data load and rebuild.
Niko’s site is the most in depth source about column store indexes that I know of. Currently there are 131 posts regarding them.
http://www.nikoport.com/columnstore/
And of course there is always Microsoft’s offication documentation.
Now that is out of the way, I will show some of the benefits I have seen using column store indexes.
First here is my table structure. It is a table that shows hourly reads for different devices. There is a table called READING which has non-clustered indexes. There is also a table called READING1 which has the same amount of rows, but it has a columnstore index. Both tables have 1.1 Billion rows
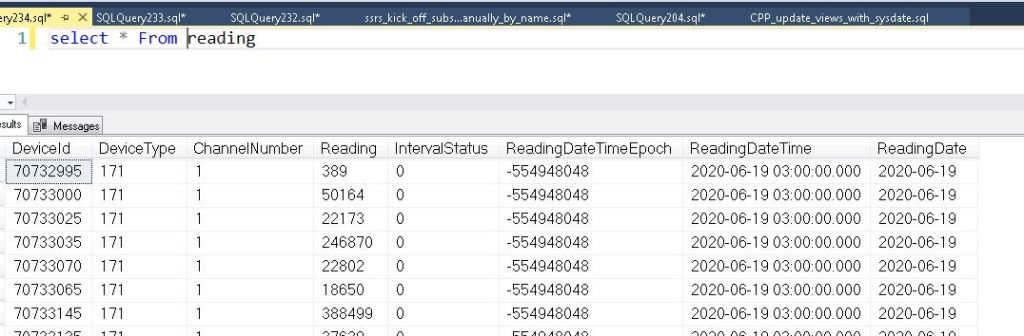
If you look at the table sizes, you can already see a benefit that the table with the columnstore index (READING1) has compressed the table to approx half the size.

Here are the indexes on the tables.
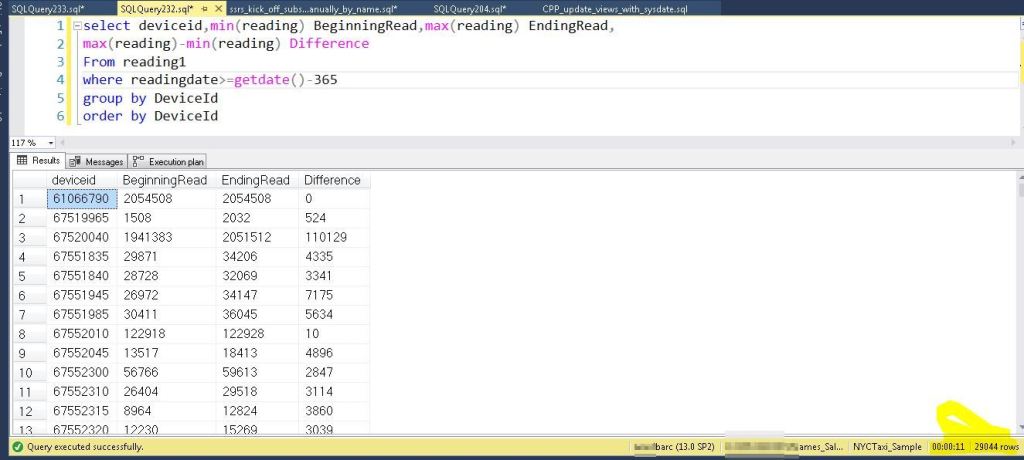
Here is a common query that gets the beginning read and most recent read for a device over the last year. Using the table without the column store index, it took just over 6 minutes.

It took over 560,000 logical reads to return the query.

Below is the execution plan showing that it used the non-clustered index.

Now here is the same query on the table with the column store index. Same amount of rows and it took 11 seconds!!! The non-clustered index table took over 6 minutes. That is a massive improvement. Yes these queries are really used, so the users are very happy.
Here are the reads that the columnstore index took. Much less since the table/index is compressed.

And here is the execution plan.
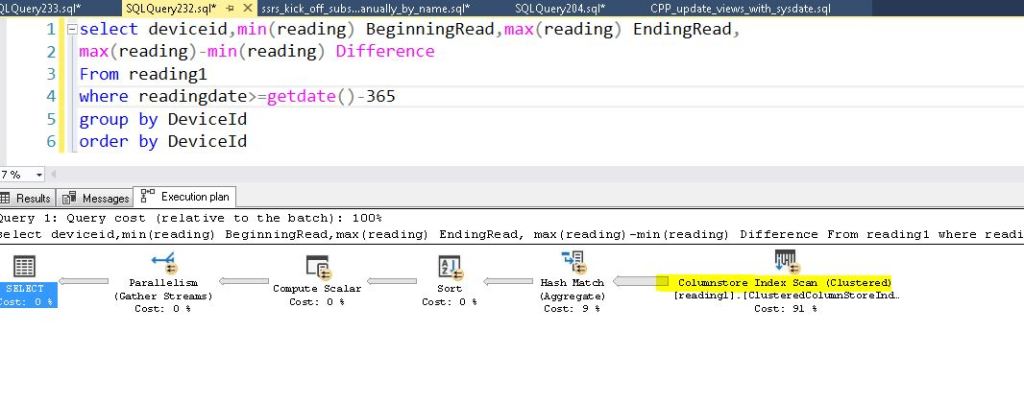
Here are the differences in the index portions. The columnstore index uses BATCH execution mode. To know the differences between these modes, please follow the links at the top of this article.

While the non-clustered index scan uses ROW execution mode.

One last test is just counting the number of reads each device has had over the year. The non-clustered index table took 2 minutes 25 seconds.
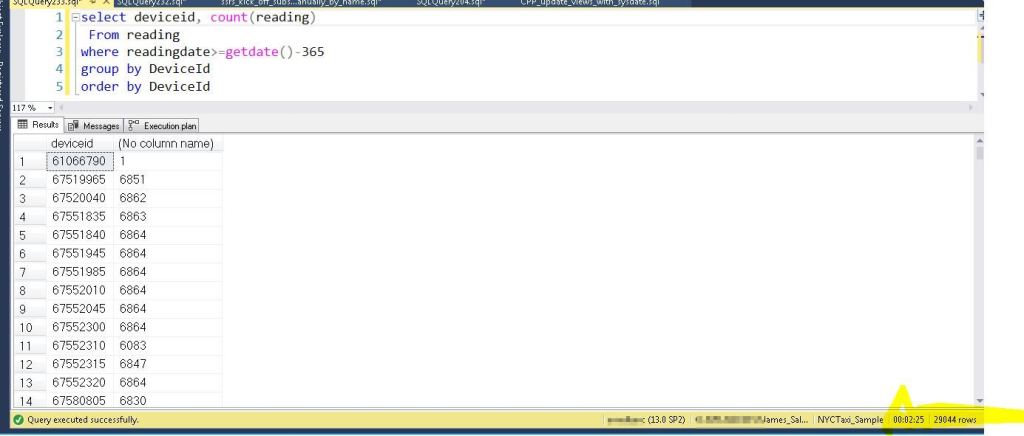
The table with the columnstore index took 4 seconds!!!!! Yes this is also a real query, so the users enjoyed benefits here also.
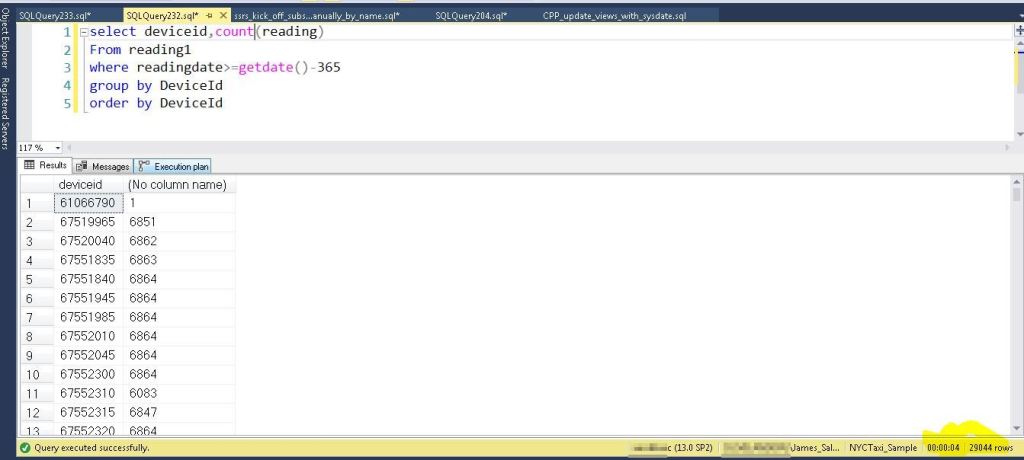
That concludes my demo of showing the speed increases of using columnstore indexes in your data warehouse environment.
If you want real, no fooling improvements do some testing and try them.
