
Duplicate data in your database? I will show you two ways on how to delete duplicate data in your Sql Server database. How does it get there? The ways are limitless, but you more than likely do not have an adequate unique index or unique constraint setup for your table.
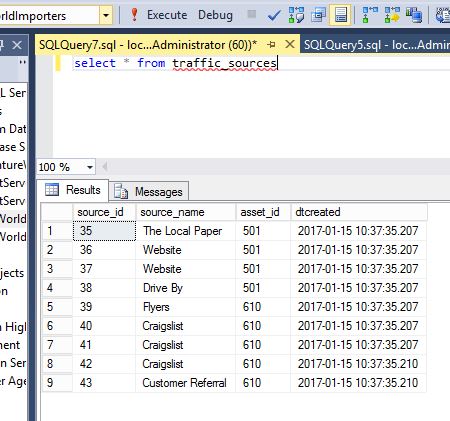
Today you are working on a database that keeps track of sales leads for a car dealership. Below you can see the sources of traffic the sales representatives use to keep track of new customers at their location.
The column names should be self explanatory, but source_id is a unique identifier for the source, source_name is the name of the source, asset_id is the dealership that is attached to the source, dtcreated is when the source was added to the system. You can see that Website was created twice for asset_id 501 and Craigslist is associated to asset_id 610 three times. Each asset_id should only have each source listed once.
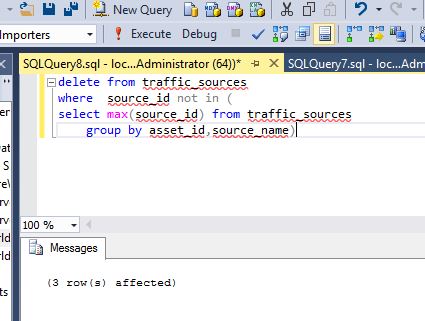
The below delete statement is one way to get rid of duplicate data. This way works if you have a unique identifier for each row (source_id). What the statement does is, starting from the inner_query, it retrieves the largest source_id from the table for each asset_id and source_name and then deletes any source that is not equal to the largest source_id for that asset_id and source_name. It is very important to make sure you have all of the unique identifiers in the group by statement. If you leave out something, it will either not delete anything or more than likely, get rid of too much stuff. Double check.
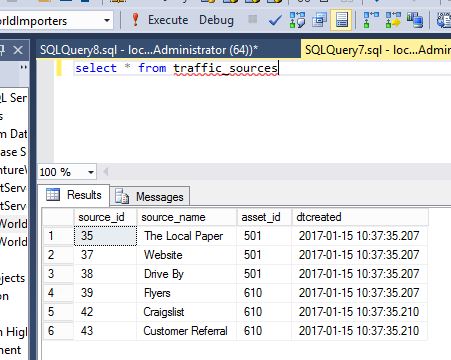
The above delete statement got rid of the three duplicate rows and if we look at the table again, we can see each asset_id does not have any duplicate rows.
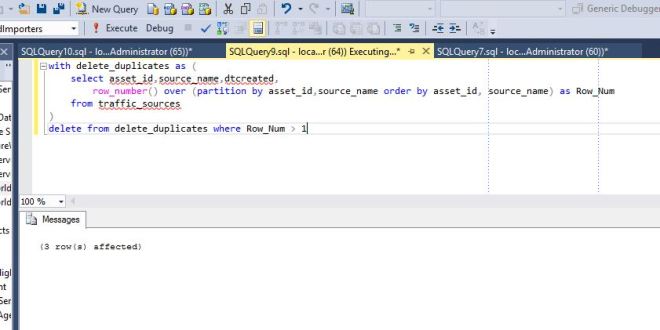
Here is another way to delete out duplicate data using common table expressions and some sql window functions.
Below is our traffic_sources data. Its the same as above with three duplicate rows, just that the source_id numbers are different.

I will break down the process into two parts, first writing the query to find the duplicate values, and then incorporating the query into a common table expression.
We want to figure out what rows are duplicates for each asset_id, so we use the row_number ranking function and partition it using the OVER clause by our unique identifiers (asset_id and source_name). Books Online does a good job of describing these statements, so here are a couple links so you can learn more about it. Over clause: https://msdn.microsoft.com/en-us/library/ms189461.aspx .
Ranking functions: https://msdn.microsoft.com/en-us/library/ms189798.aspx
This query adds a column called Row_Num which shows a 1 if it is unique or a 2,3, etc, if it is a duplicate.

Since we identified the duplicate numbers in the query above, we can now put the query into a common table expression and easily delete the duplicate values. We run the statement and it deletes out the three duplicate rows. What is a common table expression, well, Books Online explains it pretty well so I will not duplicate their explanation: https://msdn.microsoft.com/en-us/library/ms175972.aspx , but they are very useful to know about.
We look at the table again, and see that the duplicates are gone.

Summary
Duplicate data does happen. You now know how to get rid of it if it does occur. If you can, notify the vendor or your development team and ask them if some unique constraints or unique indexes can be added to the tables to prevent it in the future.
